ビデオアウトペインティングの論文を読んだので内容をまとめます。
書誌情報
Hierarchical Masked 3D Diffusion Model for Video Outpainting 2023/09, ACM MM 2023
- https://arxiv.org/abs/2309.02119 paper
- https://fanfanda.github.io/M3DDM/ project
- https://github.com/fanfanda/M3DDM/ Apache-2.0 license, 未公開
- 著者: Fanda Fan, Chaoxu Guo, Litong Gong, Biao Wang, Tiezheng Ge, Yuning Jiang, Chunjie Luo, Jianfeng Zhan
以下に掲載する画像は、他に断りない場合上記論文からの引用となります。
まとめ
前提/課題
- 映像アウトペインティングは、提供された文脈情報(映像の中間部分)に従って、映像のエッジ部分を拡張するタスク
- 動画のアウトペインティングは以下の課題がある
- 動画は、その長さとGPUのメモリ制約により複数のクリップに分割される
- 長い動画のアウトペインティングはアーチファクトの蓄積の問題に悩まされる。また、大量の計算リソースが必要
提案
- ビデオアウトペインティング(動画の画面に写っていない外周部分の生成)のための潜在拡散モデル(LDM)を提案
- LDMはビデオフレームを潜在空間にエンコードするため、メモリが少なく効率が良い
- 1つのクリップ内、および同じ映像を分割した異なるクリップ間で高い時間的一貫性を確保するために2つの手法を提案
- マスクガイドフレーム(Masked Guide Frame): 学習時に、文脈情報(=ビデオフレーム)を、マスクされていない生フレームにランダムに置き換える。モデルは文脈情報だけでなく、隣接するガイドフレームに基づいてエッジ領域を予測可能になり、品質向上につながる。推論時は、フレームを反復的かつ疎にアウトペイントすることで、以前に生成されたフレームをガイドフレームとして使用できる
- プロンプトとしてのグローバルビデオクリップ: 処理中以外のビデオから一様に g個のグローバルフレームを抽出, 特徴マップにエンコードし、クロスアテンションで現在処理中のビデオクリップのコンテキスト(ビデオクリップの中間部分)に作用させる

詳細
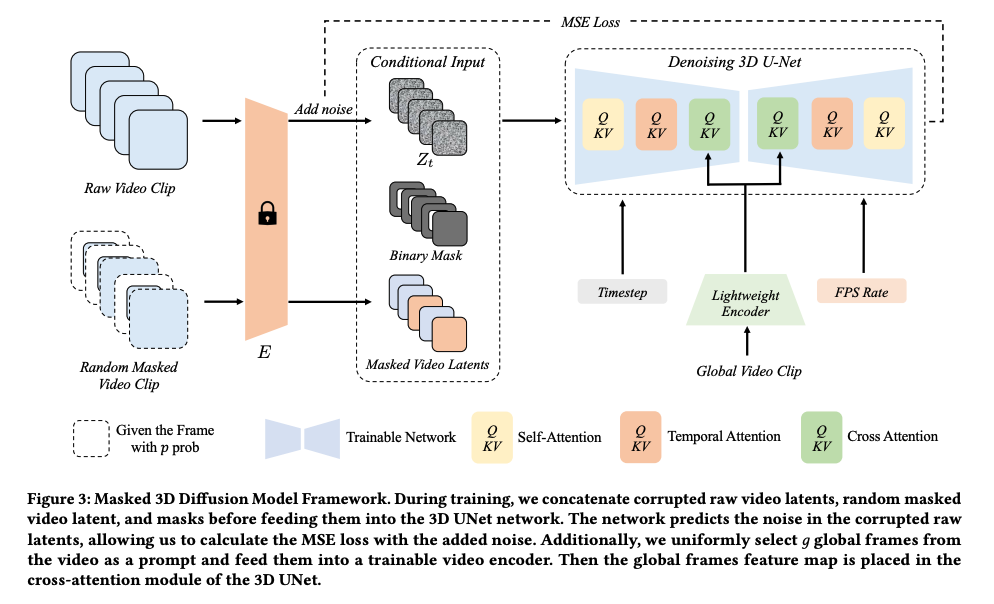
学習時の処理
- 生のビデオフレームと, 外周部分をマスクされたビデオフレームをそれぞれ固定encoderで処理してlatent vectorにする
- 以下3点を3D U-Netに入力してノイズ除去を学習(付与されたノイズを予測)
- 生ビデオフレームのlatent vectorにノイズ付与
- マスクビデオフレームのbinary mask
- マスクビデオフレームのlatent vector
- マスクビデオフレームはencoder入力前に一定の戦略(置き換えなし, 最初と最後のみ置き換え, すべてを確率0.5で置き換え)で生ビデオフレーム(マスクなし)に置き換えられる。この学習により、推論時に一度ノイズ除去して得られた画像をFPSを変えて再び入力することで、疎らな完全なフレームを得た状態でその間のフレームを補完して生成する戦略が可能になる
- マスク方法は外周の1辺, 上下, 左右, 外周全体, 画像すべて, 等の種類を一定確率で組み合わせている。”画像すべて”のマスクを含めたことで無条件生成も可能
- 以下3点を3D U-Netに入力してノイズ除去を学習(付与されたノイズを予測)
- Unet内部では以下の条件を挿入
- フレームのtime step
- 処理中の動画以外の別の動画から抽出したグローバルフレームを、外周部分はマスクした上でencodeした情報: 長い動画は一度に入力できないので、処理中のbatchに収まらなかった部分の動画も考慮するため
- 動画のFPS: FPSが異なる動画も同じモデルで処理させるため
実験設定
- WebVidデータセットで4エポック学習した後、5Mのe-commerceデータセットで3エポック微調整
- 学習は24台のA100 80GB GPUで行われ、全訓練プロセスは約2.5週間かかった
- 一度の推論で16フレームを生成, 参照するグローバルフレームも16
- テストフェーズではTesla v100 16GBでバッチサイズ2のテストサンプルを推論

コメント